We’re excited to announce that our Sage AI assistant has exited beta, using the same database of 5+ billion consumer insights trusted for years by major brands such as Target, Bank of America, and McDonald’s.
Ask Sage any question in plain English (or 100+ other languages). In seconds, you’ll receive an unparalleled glimpse into the mind of the American consumer, complete with charts and data downloads.
CivicScience is the first research technology company to meld conversational generative AI (GenAI) with real-time consumer insights at this scale. Working with this quickly evolving technology required our product development team to grapple with some challenges, and I’d like to explain our approach.
Data poses challenges for LLMs
As Sage insights will drive customers’ critical business decisions, our data scientists and engineers had to solve two key issues: guarding against GenAI hallucinations and taking advantage of always-changing, complex petabyte-scale data.
The solution to both came as a core innovation in working with large language models (LLMs).
While typical LLM chatbots resemble search engines on steroids, summarizing vast amounts of text, Sage operates differently due to working with quantitative data.
Although CivicScience has published thousands of in-depth research reports, they only touch the tip of the iceberg and can’t adequately cover the breadth of our 600,000 poll questions, which increase by hundreds daily. Answering “Tell me about luxury-car-buying habits of middle-aged, college-educated men in the Northeast last month” requires cross-tabulating several questions, screened through the lenses of demography, geography, and time. There are near-infinite permutations to how our customers want to view CivicScience data.
The answer changes daily, with new conversations with 500,000 American consumers on 20,000 different topics, generating millions more insights. We truly study everything constantly.
So Sage needs access to live data to create custom, ad-hoc research reports in seconds while preventing the AI from fabricating results, an unfortunate random behavior of these complex systems.
Building an AI sandwich
To address data complexity and trust concerns, Sage relies on an “AI sandwich,” blending LLM techniques of domain factuality enhancement (DFE) and retrieval augmented generation (RAG).
In this sandwich, OpenAI’s newest LLM – GPT-4 Turbo, released earlier this month – is the bread, and CivicScience’s core data systems are the meat. Once a user enters an inquiry, here’s what Sage’s custom GPT interface code does next:
- Thinking like a research analyst determines the best-suited poll questions and the appropriate segmentation and time windows.
- Constructs API calls to our Cascabel data engine for detailed retrieval and analysis against live data.
- Synthesizes API results into comprehensible narratives and dynamically generated charts showcasing trends in consumer sentiment. Users can ask follow-up questions to dive more deeply.
Ask ChatGPT and Sage the same question, and they will often come back with different answers. ChatGPT may sometimes be unmoored from reality (aka hallucinations) due partly to its training on trillions of web pages of varying quality, compared to Sage’s exclusive reliance on CivicScience first-party data.
Our quest for the highest levels of veracity also includes footnotes, with every detailed Sage insight tied back to source data with links to our InsightStore application. Users without InsightStore access can download rich Excel workbooks to enable detailed offline analysis.
To learn more about how CivicScience is revolutionizing AI in consumer research and to explore Sage’s capabilities, please click here or contact us.
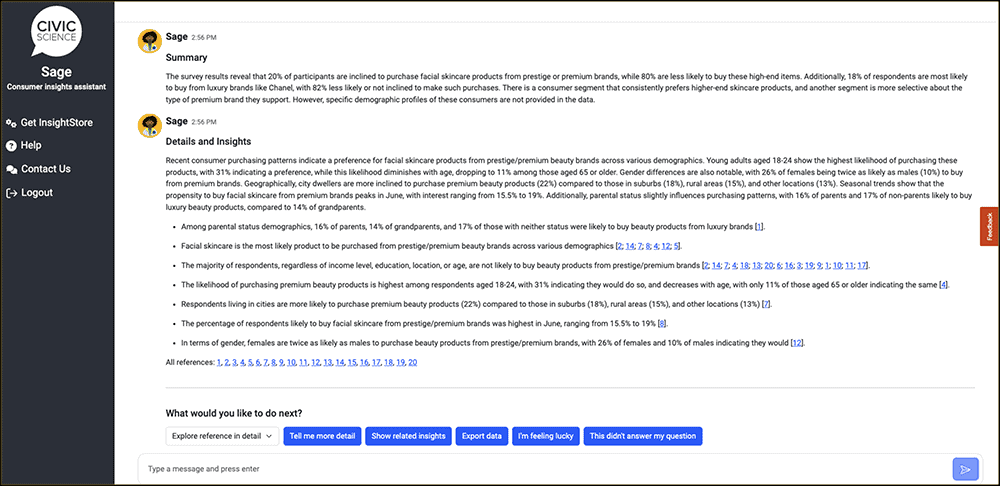
Sage webchat interface. Slack and Microsoft Teams versions will be available soon.








